Parametrization
The Student's t-likelihood is defined such that:
\[\sqrt{s_i \tau}(y_i - \eta_i) \sim T_{\nu}\]
for a continuous response vector \(\pmb{y} = (y_1, y_2, \ldots, y_n)\), where:
\(\pmb{y} = (y_1, y_2, \ldots, y_n)\) represents the observed continuous response values.
\(\pmb{\eta} = (\eta_1, \eta_2, \ldots, \eta_n)\) is the linear predictor.
\(\tau > 0\) is the precision parameter, controlling the spread of the distribution.
\(s_i > 0\) is a fixed scaling factor for observation \(i\) (default \(s_i = 1\)).
\(T_{\nu}\) is a reparameterized standard Student's t-distribution with \(\nu > 2\) degrees of freedom, scaled to have unit variance for all values of \(\nu\).
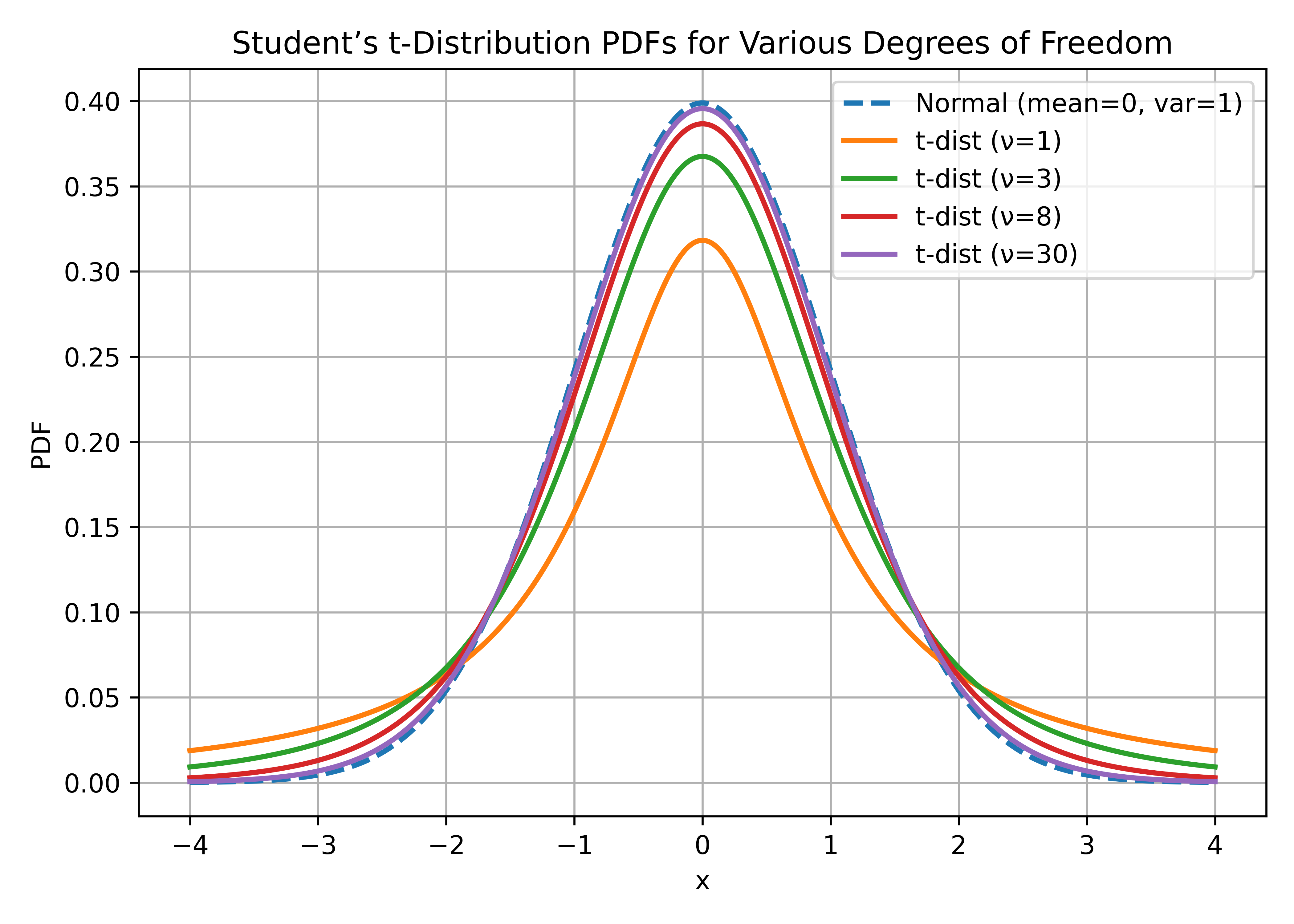
Figure 1 shows how the Student's t-distribution PDF changes as the degrees of freedom \(\nu\) vary. When \(\nu\) is small, the distribution has heavy tails, offering robustness against outliers. As \(\nu \to \infty\), the t-distribution converges to the standard normal distribution.
Mean and Variance
For each observation \(y_i\):
\[\text{E}(y_i) = \eta_i, \quad \text{Var}(y_i) = \frac{1}{s_i \tau}\]
The mean equals the linear predictor (identity link), and the variance is controlled by the precision \(\tau\) and the observation-specific scale \(s_i\). Note that the t-distribution is reparameterized to have unit variance for all values of \(\nu\), so the variance formula is the same as for the Gaussian distribution.
Link Function
The mean is linked to the linear predictor using the identity link (default):
\[\mu_i = \eta_i, \quad i = 1, 2, \ldots, n\]
In vector form:
\[\pmb{\mu} = \pmb{\eta}\]
Available link functions: default, identity.
Hyperparameters
The Student's t-likelihood has two hyperparameters: precision \(\tau\) and degrees of freedom \(\nu\). Both are represented internally via transformations to ensure they remain within valid ranges.
Hyperparameter \(\theta_1\) (precision)
Key: prec
The precision parameter \(\tau\) is represented internally as:
\[\theta_1 = \log(\tau)\]
Thus, \(\theta_1\) can take any real value, ensuring \(\tau > 0\). The prior is defined on \(\theta_1\). The default configuration uses a log-gamma prior with shape 1 and rate 5e-05, starting at \(\theta_1 = 0\) (corresponding to \(\tau = 1\)).
Hyperparameter \(\theta_2\) (degrees of freedom)
Key: dof
The degrees of freedom \(\nu\) is represented internally as:
\[\theta_2 = \log(\nu - 2)\]
This ensures \(\nu > 2\), which is required for the
variance to exist. The prior is defined on \(\theta_2\).
The default configuration uses a PC prior (pc.dof) with parameters [15, 0.5],
which penalizes deviations from the base model (Gaussian with \(\nu = \infty\)).
When translated into control['family']['hyper'], the default entries look like:
control = {
'family': {
'hyper': [
{
'id': 'prec',
'prior': 'loggamma',
'param': [1, 5e-05],
'initial': 0,
'fixed': False,
},
{
'id': 'dof',
'prior': 'pc.dof',
'param': [15, 0.5],
'initial': 5,
'fixed': False,
},
]
}
}
Each entry in control['family']['hyper'] may contain these keys:
id- Hyperparameter identifier (precordof; positional aliasestheta1/theta2also accepted).prior- Prior distribution nameparam- Prior parameters (list)initial- Initial value on the internal scale (log forprec, log(\(\nu - 2\)) fordof)fixed- Whether to fix the hyperparameter (True/False)
Both hyperparameters accept any prior from the prior registry. The most commonly useful choices are:
| Slot | Prior | Param shape | Use when |
|---|---|---|---|
prec | loggamma (default) | [shape, rate], both positive | Conjugate prior on the log-precision. |
pc.prec | [U, alpha] with P(sd > U) = alpha | Penalised-complexity prior. | |
normal / gaussian | [mean, precision] on \(\theta_1\) | Soft Gaussian on the log-precision. | |
flat | [] | Improper flat. | |
logtnormal | [location, scale] | Truncated-normal on \(\theta_1\). | |
dof | pc.dof (default; alias pcdof) | [U, alpha] | Penalised-complexity prior on degrees of freedom; recommended. |
normal / gaussian | [mean, precision] on \(\theta_2\) | Soft Gaussian on the log-shifted dof. | |
logtnormal | [location, scale] | Truncated-normal on \(\theta_2\). |
Either hyperparameter can be pinned at a known value by setting fixed=True (no prior required). Unknown prior names raise a clear pyinla safety check: unknown prior '...' error before the engine runs; wrong param length similarly trips a safety error. Note that some prior/data combinations may pass the safety layer but fail to converge in the INLA C engine.
Validation Rules
pyINLA enforces several validation rules for Student's t models to ensure correct specification:
Not Allowed Arguments
The following arguments are not allowed for student-t and will raise PyINLAError:
E(exposure) - Only allowed for poisson/nbinomialNtrials- Only allowed for binomial/xbinomial/betabinomial/nbinomial2control['family']['variant']- Not supported for student-t
Scale (optional)
Key: scale
The scale argument is optional (default \(s_i = 1\)). When provided:
All values must be strictly positive (> 0)
Length must match the number of observations
Hyperparameters
Key: control['family']['hyper']
When configuring hyperparameters (see the Hyperparameters section above for the full prior registry and key listing):
If
prioris omitted, the schema default is used (loggammawithparam=[1, 5e-05]forprec;pc.dofwithparam=[15, 0.5]fordof). A fixed entry can also omitpriorandparam.If specified, the prior name must be in the registry. Unknown names raise
pyinla safety check: unknown prior.paramlength must match the prior's expected count (loggamma/pc.precadditionally require positive values where applicable).
Allowed Link Functions
Key: control['family']['link']
These link functions are supported:
defaultidentity
Specification
family="t"(lowercase;"T"is also accepted and normalized)Required arguments:
\(\pmb{y}\): response vector of continuous values.
Optional arguments:
\(\pmb{s}\): scale vector (keyword
scale, default \(s_i = 1\)).
Notes
- The t-distribution is reparameterized to have unit variance for all values of \(\nu\). The standard t\(_\nu\) has variance \(\nu/(\nu-2)\); the reparameterized form divides by \(\sqrt{\nu/(\nu-2)}\) (equivalently, multiplies by \(\sqrt{(\nu-2)/\nu}\)) so that \(\text{Var}(T_\nu) = 1\) for all \(\nu > 2\).
- The degrees of freedom must satisfy \(\nu > 2\) for the variance to exist. This is enforced by the internal transformation \(\theta_2 = \log(\nu - 2)\).
- As \(\nu \to \infty\), the t-distribution converges to the normal distribution.
- The PC prior (
pc.dof) on degrees of freedom penalizes deviations from the base model (normal distribution with \(\nu = \infty\)). - The scale parameter \(s\) can be observation-specific, enabling heteroscedastic modeling.
- To fix degrees of freedom at a specific value \(\nu^*\),
set
initial=np.log(nu_star - 2)andfixed=Truein thedofhyperparameter specification.