Student's t-Distribution Regression
A tutorial on robust Bayesian regression using the Student's t-distribution, which provides resistance to outliers through heavier tails than the Gaussian.
Introduction
The Student's t-distribution extends the normal distribution with heavier tails, providing robustness against outliers. When data may contain extreme values or when modeling errors with heavier tails than Gaussian, the t-distribution is a natural choice.
As the degrees of freedom $\nu$ increases, the t-distribution approaches the normal distribution. With smaller $\nu$, the distribution has heavier tails.
The Model
For each observation $i = 1, \ldots, n$, the response $y_i$ follows a reparameterized Student's t-distribution:
where:
- $y_i \in \mathbb{R}$ is the continuous response
- $\eta_i = \beta_0 + \beta_1 x_i$ is the linear predictor
- $\tau > 0$ is the precision parameter
- $s_i > 0$ is an optional scale factor (default = 1)
- $\nu > 2$ is the degrees of freedom
- $T_{\nu}$ is reparameterized to have unit variance
Hyperparameters
The t-distribution has two hyperparameters:
- Precision ($\tau$): $\theta_1 = \log(\tau)$, with a log-gamma prior by default
- Degrees of freedom ($\nu$): $\theta_2 = \log(\nu - 2)$, with a PC prior (
pc.dof) by default
The constraint $\nu > 2$ ensures the variance exists. The PC prior penalizes deviation from the Gaussian ($\nu = \infty$).
Dataset
The dataset contains $n = 300$ observations:
| Column | Description | Type |
|---|---|---|
y | Continuous response (t-distributed errors) | float |
x | Covariate | float |
Implementation in pyINLA
import pandas as pd
from pyinla import pyinla
# Load data
df = pd.read_csv('dataset_t_regression.csv')
# Define model: y ~ 1 + x
model = {
'response': 'y',
'fixed': ['1', 'x']
}
# Fit with Student's t family
result = pyinla(
model=model,
family='T', # uppercase T
data=df
)
# View results
print(result.summary_fixed)
print(result.summary_hyperpar)
Custom Priors
You can customize priors on both hyperparameters:
# Custom priors on precision and degrees of freedom
control = {
'family': {
'hyper': [
{
'id': 'prec',
'prior': 'loggamma',
'param': [1, 0.01],
},
{
'id': 'dof',
'prior': 'pc.dof',
'param': [10, 0.5], # P(nu > 10) = 0.5
},
]
}
}
result = pyinla(
model=model,
family='T',
data=df,
control=control
)
Results and Diagnostics
The posterior summaries recover the true parameters. Outlier observations visible in the residuals are naturally handled by the heavy-tailed t-distribution.
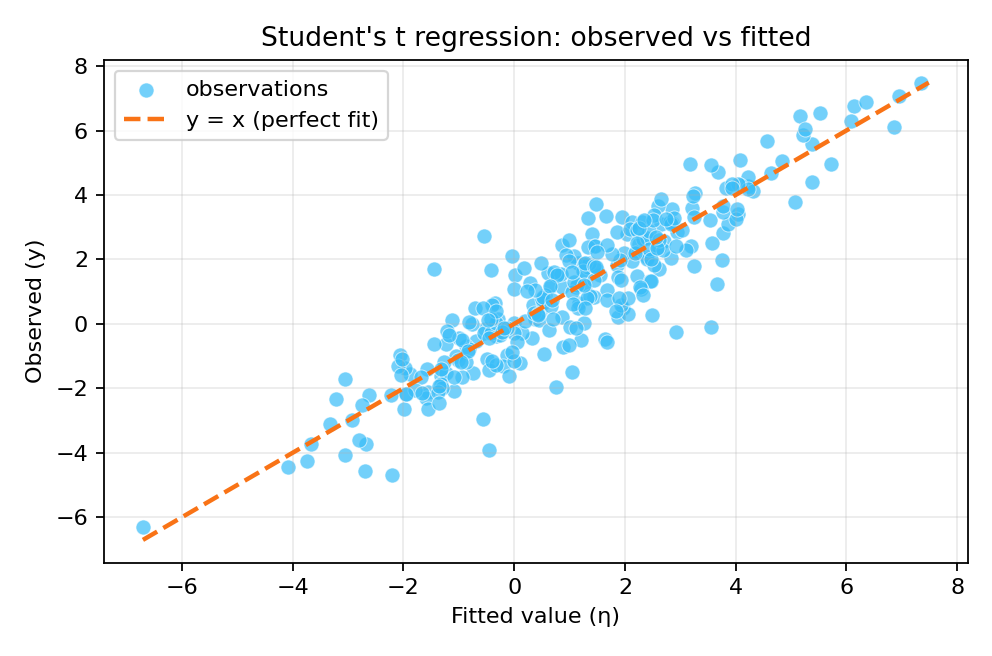
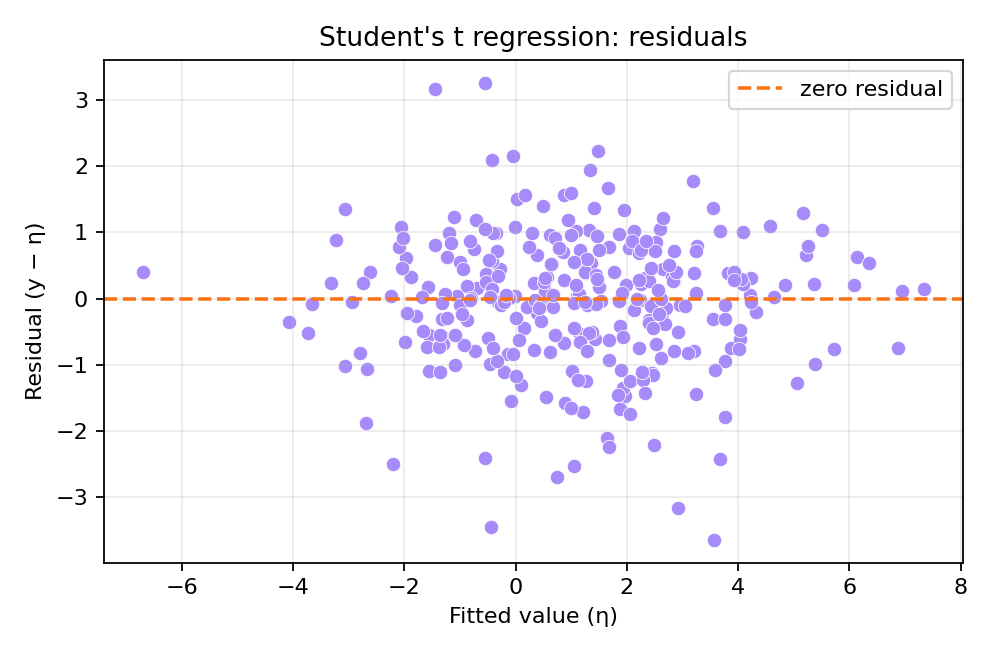
To reproduce these figures locally, download the render_t_plots.py script and run it alongside the CSV dataset.
Data Generation (Reference)
The dataset was simulated with:
import numpy as np
import pandas as pd
rng = np.random.default_rng(2026)
n = 300
nu = 5 # degrees of freedom
x = rng.normal(0, 1, size=n)
eta = 1 + 2 * x
# t-distributed errors scaled for unit variance
t_errors = rng.standard_t(df=nu, size=n)
y = eta + t_errors / np.sqrt(nu / (nu - 2))
df = pd.DataFrame({'y': y, 'x': x})
# df.to_csv('dataset_t_regression.csv', index=False)